Xcode × GLM Coding Plan,和报错说拜拜!
我尝试在 Xcode 中接入智谱的 GLM Coding Plan 模型做 AI 辅助编程,结果配置好官方地址后,一对话就报错:The data couldn't be read because it is missing。查了一圈发现是智谱 API 的响应格式和 Xcode 期望的 Claude API 格式存在差异——部分必要字段缺失,导致 Xcode 解码失败。
在官方完全兼容之前,我写了一个本地代理服务来解决适配问题。
最终产物是一个不到 500 行 Rust 代码的本地代理服务 glm-coding-xcode-proxy,在 Xcode 和智谱 API 之间做协议转发,彻底解决了这个问题。本文分享整个实现过程和设计思路。
问题根源:为什么直连会失败?
Xcode 26.3 支持配置外部模型提供者进行 AI 辅助编程。在 Xcode Settings 中添加智谱 Bigmodel 作为 Internet Hosted 模型提供者,填写官方地址 https://open.bigmodel.cn/api/anthropic,看起来一切正常。
配置本身就可能验证失败:
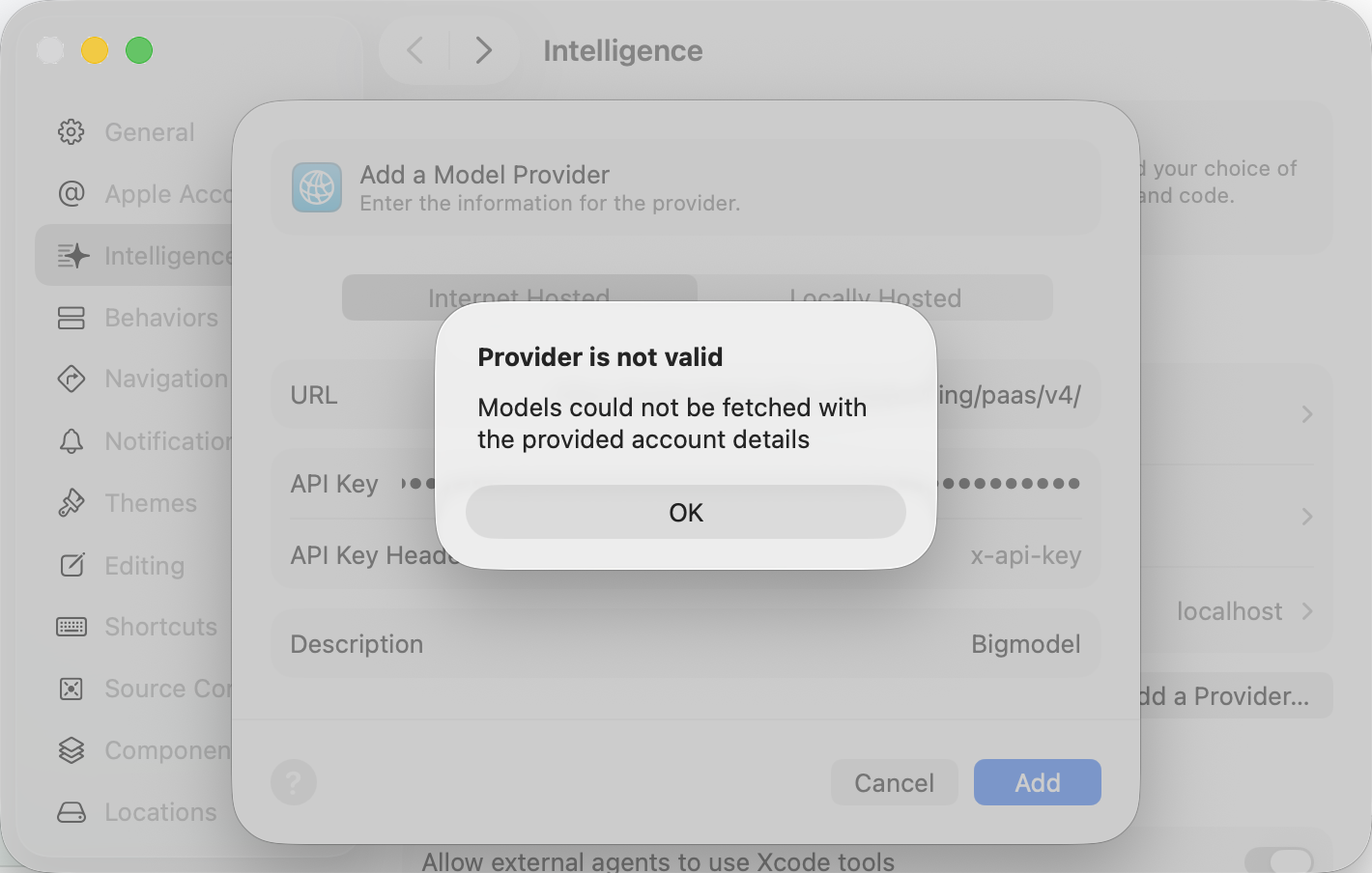
即使配置通过,对话时也会报错:
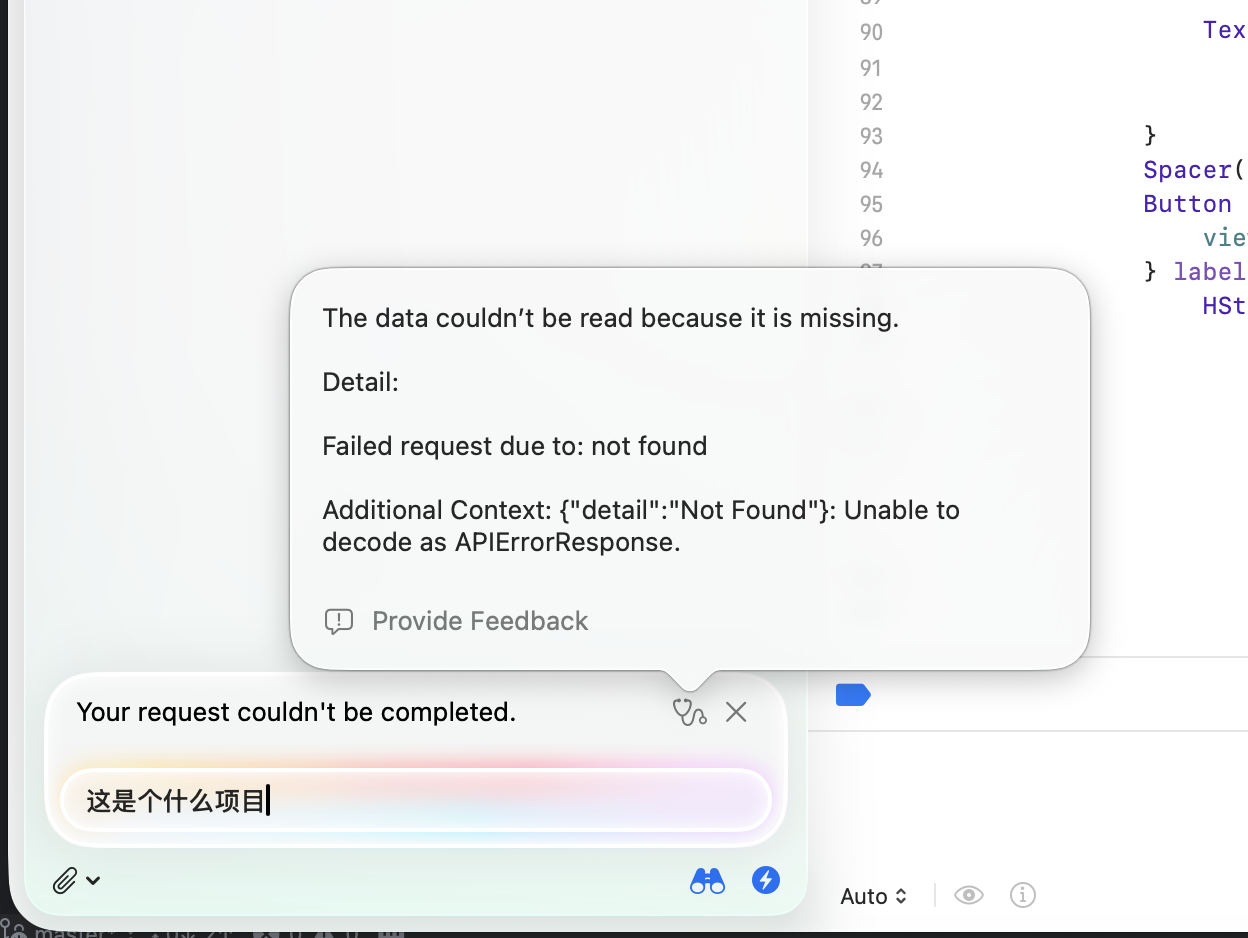
Xcode 的错误信息很直白:
The data couldn't be read because it is missing.
Unable to decode as APIErrorResponse.
核心矛盾:Xcode 内置的是 Claude API 客户端,对响应格式的要求非常严格。直连智谱 /api/anthropic 端点时,虽然请求能发出去,但返回的响应格式不完全符合 Xcode 的预期,导致解码失败。而智谱的 /api/coding/paas/v4 端点提供了 OpenAI 兼容的 API 格式,与 Xcode 的解析器能够正常配合——但这个端点需要通过 Locally Hosted 模式接入,代理就是用来做这个协议适配的。
解决思路:本地代理转发
问题清楚了,解决方案也很直觉——在中间加一层代理:
Xcode (Claude API 客户端)
|
v
localhost:8890 --[axum HTTP server]--> ZhipuClient
| |
| /v1/models v
| /v1/chat/completions https://open.bigmodel.cn/api/coding/paas/v4代理核心做三件事:
- 监听本地端口,接收 Xcode 发来的请求(Locally Hosted 模式下走 OpenAI 兼容格式)
- 协议适配:将请求转发到智谱
/api/coding/paas/v4端点,注入 API Key 认证,处理请求格式的对接 - 响应回传:非流式场景返回 JSON 响应;流式场景直接透传 SSE 字节流,并设置正确的
Content-Type头
在 Xcode 中,只需要把模型提供者类型从 "Internet Hosted" 改为 "Locally Hosted",端口填 8890:
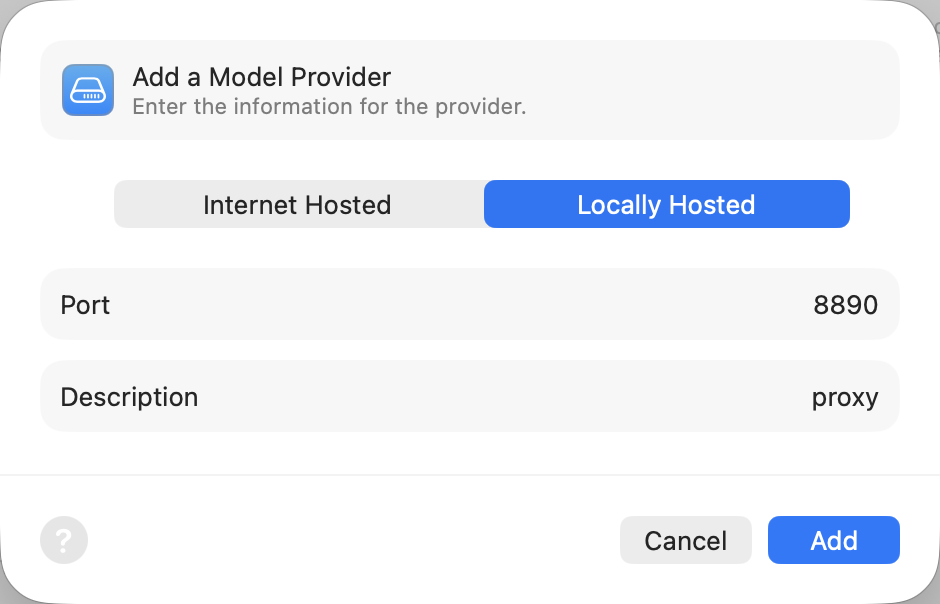
配置完成后即可正常对话:
为什么选 Rust?
做这种代理服务,语言选择很多——Node.js、Python、Go 都能写。但我选 Rust 有几个实际理由:
| 考量维度 | Rust | Node.js | Python |
|---|---|---|---|
| 内存占用 | ~5.6MB(实测) | ~30MB | ~20MB |
| 流式处理 | 原生 async/await,零成本抽象 | 事件循环,但 GC 可能卡顿 | asyncio 可用,但生态稍弱 |
| 二进制分发 | 单文件,无依赖 | 需要 Node runtime | 需要 Python 环境 |
| 长期运行稳定性 | 无 GC,无内存泄漏风险 | 长时间运行可能有内存增长 | GIL 限制并发 |
对于一个要长期运行在后台的代理服务,低内存占用、无 GC 卡顿、单文件分发是硬需求。实测内存占用仅 5.6MB,Rust 在这个场景下几乎是完美的选择。
技术实现
整体架构
项目是一个单体 CLI 应用,基于 tokio + axum 构建,总共不到 500 行代码,10 个源文件:
src/
├── main.rs # 入口,CLI 分发,服务器启动
├── cli.rs # clap 子命令定义
├── config.rs # 配置管理(KEY=VALUE 格式)
├── client.rs # 智谱 API 客户端
├── handlers.rs # HTTP 请求处理器
├── models.rs # 请求数据模型
├── error.rs # 统一错误处理
├── retry.rs # 异步重试逻辑
└── commands/
├── mod.rs
├── config_cmd.rs # config 子命令
└── service_cmd.rs # service 子命令(macOS launchd)API 客户端:ZhipuClient
核心是 client.rs 中的 ZhipuClient,封装了对智谱 API 的三种调用:
rust
/// 智谱 API 客户端
pub struct ZhipuClient {
client: Client, // reqwest HTTP 客户端
config: Config, // 配置信息
}
impl ZhipuClient {
// 获取模型列表
pub async fn list_models(&self) -> Result<Value, ApiError>
// 非流式聊天完成
pub async fn chat_completion(&self, request: &ChatCompletionRequest) -> Result<Value, ApiError>
// 流式聊天完成(SSE)
pub async fn chat_completion_stream(&self, request: &ChatCompletionRequest) -> Result<Response<Body>, ApiError>
}流式处理是这里最关键的部分。Xcode 的 AI 对话使用 SSE(text/event-stream)进行流式响应,代理必须原样透传字节流,不能做 JSON 解析——因为智谱的 SSE 格式本身就不完全兼容 Claude,强行解析反而会出错。
rust
// 流式请求的核心逻辑
async fn make_stream_request(&self, request: &ChatCompletionRequest) -> Result<Response<Body>, ApiError> {
let response = self.client
.post(&url)
.header("Authorization", format!("Bearer {}", self.config.zhipu_api_key))
.json(request)
.send()
.await?;
// 直接透传字节流,不做解析
let stream = response.bytes_stream();
let body = Body::from_stream(stream);
let response = Response::builder()
.header(header::CONTENT_TYPE, "text/event-stream")
.header(header::CACHE_CONTROL, "no-cache")
.header(header::CONNECTION, "keep-alive")
.body(body)?;
Ok(response)
}这里有个设计决策:流式场景下直接透传字节流,不做 JSON 解析和重组。 智谱 Coding Plan API 的流式 SSE 输出格式与 Xcode 的解析器能够正常配合,问题主要出在直连
/api/anthropic端点时的非流式响应结构上。通过代理切换到/api/coding/paas/v4端点并处理好认证和头信息,两种模式都能正常工作。
异步重试机制
网络请求不可能 100% 成功,代理服务必须有重试能力。我用 Rust 的 async trait 实现了一个通用的重试函数:
rust
pub async fn with_retry<T, E, F, Fut>(
operation: F, // 异步操作
max_retries: u32, // 最大重试次数
base_delay_ms: u64, // 基础延迟
) -> Result<T, E>
where
F: Fn() -> Fut,
Fut: std::future::Future<Output = Result<T, E>>,
{
for attempt in 1..=max_retries {
match operation().await {
Ok(result) => return Ok(result),
Err(e) => {
if attempt < max_retries {
let delay = base_delay_ms * attempt as u64; // 线性递增
sleep(Duration::from_millis(delay)).await;
}
}
}
}
Err(last_error)
}采用线性递增延迟策略(第 1 次等 1s,第 2 次等 2s,第 3 次等 3s),比固定间隔更合理——给上游 API 更多恢复时间,同时不会像指数退避那样等待过久。
统一错误处理
代理服务作为中间层,需要把各种错误(网络超时、上游 500、内部异常)统一转化为 Xcode 能理解的格式:
rust
pub enum ApiError {
UpstreamError(String), // 上游 API 错误 → 502 Bad Gateway
NetworkError(String), // 网络错误 → 500 Internal Server Error
InternalError(String), // 内部错误 → 500 Internal Server Error
}每个错误类型都实现了 IntoResponse,确保无论什么异常,Xcode 都能收到一个合法的 JSON 错误响应,而不是连接中断。
macOS 服务管理
作为 macOS 上的后台服务,需要集成 launchd。项目通过 service 子命令一键完成:
bash
glm_coding_xcode_proxy service install # 自动生成 plist 并启动
glm_coding_xcode_proxy service status # 查看状态、PID、日志路径
glm_coding_xcode_proxy service stop # 停止服务plist 配置了 KeepAlive,服务异常退出后会自动重启。日志输出到 ~/Library/Logs/glm-coding-xcode-proxy/,方便排查问题。
使用方式
安装
从 GitHub Releases 下载预编译二进制:
bash
chmod +x glm_coding_xcode_proxy
sudo mv glm_coding_xcode_proxy /usr/local/bin/或从源码编译:
bash
git clone https://github.com/cicbyte/glm-coding-xcode-proxy.git
cd glm-coding-xcode-proxy
cargo build --release配置与启动
bash
# 设置智谱 API Key
glm_coding_xcode_proxy config set KEY your-api-key-here
# 启动代理
glm_coding_xcode_proxy首次运行时如果未配置 API Key,会交互式引导输入。
Xcode 配置
- 打开 Xcode → Settings → Components → Model Providers
- 点击 "+" 添加 Locally Hosted 提供者
- 端口填写 8890
- 开始对话
配置项一览
| 配置项 | 说明 | 默认值 |
|---|---|---|
KEY |
智谱 API Key(必需) | 无 |
HOST |
监听地址 | 127.0.0.1 |
PORT |
监听端口 | 8890 |
MAX_RETRIES |
最大重试次数 | 3 |
RETRY_DELAY |
重试基础延迟(ms) | 1000 |
REQUEST_TIMEOUT |
请求超时(ms) | 60000 |
几点实战经验
1. 流式透传比格式转换更靠谱
最初我想在代理层做完整的 JSON 格式转换,把智谱的响应改写成 Claude 格式再返回给 Xcode。但实际操作中发现,流式 SSE 的逐块解析和重新组装非常复杂。最终选择了"切换到兼容端点 + 认证注入 + 流式透传"的策略——利用智谱 /api/coding/paas/v4 端点本身的兼容性,代理只负责协议桥接和错误兜底,效果很好。
2. 线性递增延迟够用了
指数退避(1s, 2s, 4s, 8s...)虽然更"标准",但对于这个场景来说过于保守。智谱 API 通常几秒内就能恢复,线性递增(1s, 2s, 3s)在可靠性和响应速度之间取得了更好的平衡。
3. 配置文件用最简单的格式
没有选 TOML、YAML 或 JSON,而是用了最朴素的 KEY=VALUE 格式。对于一个只需要存 6 个配置项的工具来说,引入 serde 的配置文件解析纯属过度设计。手动解析几行文本反而更直观,也更容易让用户直接 vim 编辑。
4. macOS 安全限制要提前处理
下载的二进制文件首次运行会被 macOS Gatekeeper 拦截。用户需要在「系统设置 → 隐私与安全性」中手动放行。这个坑在 README 里写清楚了,但如果你要给别人用,最好提前说一声。
总结
glm-coding-xcode-proxy 核心代码不到 500 行,覆盖了以下功能:
- 完整的 HTTP 代理转发(流式 + 非流式)
- 异步重试机制
- 统一错误处理
- CLI 配置管理
- macOS launchd 服务集成
- CI 自动构建发布
实测二进制约 6MB,内存常驻 5.6MB,作为后台服务几乎无感。如果你也在用 Xcode 做开发,并且购买了智谱的 Coding Plan,可以试试这个工具。
Share